파이토치 위키독스 공부하기
08-01 합성곱과 출링
합성곱 신경망은 이미지 처리에 탁월한 신경망이다.
합성곱층과 풀링층으로 구성된다. 아래의 그림은 합성곱 신경망의 예다.

CONV=합성곱 연산
합성곱 연산의 결과가 ReLU를 지나는 이 과정이 합성곱층 이라고 한다.
그 후 POOL구간을 지나는데 이것이 풀링 연산이며 풀링층이라고 한다.
1. 합성곱 신경망의 대두
손글씨를 다층 퍼셉트론으로 분류한다고 하면,
이미지를 벡터( 1차원 텐서 )로 변환하고 다층 퍼셉트론의 입력층으로 사용해야 한다.
벡터로 바꾸면 다음과 같다.

변환후의 벡터는 사람도 기계도 원래 어떤 이미지 였는지 구분하기 어렵다.
벡터로 표현된 방식은 공간적인 구조 정보(거리가 가까운 어떤 픽셀들끼리는 어떤 연관이 있고, 어떤 픽셀들끼리는 값이 비슷하거나 등을 포함하는지)가 유실된 상태라
이미지의 공간적인 구조 정보를 보존하면서 학습할 수 있는 방법이 필요했다
이를 위해 합성곱 신경망을 쓴다.
2. Channel(depth)
기계는 이미지, 글자보다는 숫자(텐서)를 더 잘 처리할 수 있다.
이미지는 높이x너비x채널의 3차원 텐서이다.
채널은 색 성분을 의미한다.
흑백 이미지는 채널 수가 1이며 각 픽셀은 0~255의 값을 가진다.

컬러 이미지는 RGB로 채널 수가 3개이다.
하나의 픽셀은 삼원색의 조합으로 이루어진다.
높이가 28,높이가 28인 컬러이미지가 있다면
이 이미지 텐서는 28x28x3 크기의 3차원 텐서이다
3. 합성곱 연산(Convolution opration)
합성곱층은 합성곱 연산을 통해서 이미지 특징을 추출하는 역할이다.
kernel 또는 filter라는 nxm크기의 행렬이며
height x width크기의 이미지를 처음부터 끝까지 겹치며 훑으며 nxm크기의 겹쳐지는 부분의 각 이미지와 커널의 원소 값을 곱해서 모두 더한 값을 출력으로 하는것이다.
이 때 이미지의 가장 왼쪽 위부터 가장 오른쪽까지 순차적으로 훑는다.
kernel은 일반적으로 3x3, 5x4를 사용
example)
3x3크기 커널로 5x5의 이미지 행렬에 합성곱 연산을 수행하는 과정을 보자
한번의 연산을 1step이라고 할때 합성곱 연산의 네번째 스텝까지 이미지와 식으로 쵸현해보자

최종결과인 feature map은 다음과 같다

커널의 크기나 커널의 이동 범위(stride)또 한 사용자가 지정할 수 있다.
4. Padding
특성맵은 입력이미지보다 크기가 작다.
만약 합성곱층을 여러개 쌓았다면 최종적으로 얻은 특성맵은 초기 입력보다 아주 작은을 것이다.
합성곱 연산 이후에도 특성맵 크기가 입력의 크기와 동일하게 하고 싶다면 패딩을 사용하면 된다.

패딩은 합성곱 연산 전에 입력 가장자리에 지정된 폭만큼 행과 열을 추가하는 것이다.
주로 값 0으로 채우는 제로 패딩을 사용한다.
위의 그림은 5x5 이미지에 1폭짜리 제로 패딩을 사용한 것이다
스트라이드가 1일때 3x3크기 커널을 쓴다면 1폭짜리 제로패딩을 사용하고
5x5 크기의 커널을 쓴다면 2폭 짜리 제로 패딩을 사용하면 크기를 보존할 수 있다.
5. 가중치와 편향
1) 합성곱 신경망의 가중치
- 다층 퍼셉트론을 먼저 복습해보자
다층 퍼셉트론으로 3x3이미지를 처리한다고 가정하자
이미지를 크기9의 벡터로 만들었다. 입력층은 9개의 뉴론을 가진다.
그 후 4개의 뉴론을 가지는 은닉층을 추가하면 다음과 같이 된다.
연결선은 가중치이다.

- 이제 합성곱 신경망으로 3x3이미지를 처리한다고 해보자
2x2 커널을 쓰고 스트라이드는 1이다.
합성곱 신경망에서 가중치는 커널 행렬의 원소들이다.

최종적으로 특성맵을 얻기 위해서는 동일한 커널로 이미지 전체를 훑으며 합성곱 연산을 진행한다.
그러면 사용되는 가중치는 w0,w1,w2,w3뿐이다.
합성곱 연산마다 이미지의 모든 픽셀을 사용하는 것이 아니라
커널과 맵핑되는 픽셀만을 입력으로 사용하는 것을 볼 수 있다.
결론적으로 합성곱 신경망은 다층 퍼셉트론 보다 훨씬 적은 수의 가중치를 사용하고 공간적 구조 정보를 보존한다
다층 퍼셉트론 은닉층 에서는 가중치 연산 후 비선형성을 추가하기 위해 활성화 함수에 통과시켰다
합성곱 신경망 은닉층에서도 그랬다. 합성곱 연산으로 얻은 특성맵은 활성화 함수를 지나게 하여 비선형성이 추가된다.
이 떄 렐루 계열이 주로 쓰인다.
합성곱 연산을 통해 특성맵을 얻고 활성화 함수를 지나는 연산을 하는 합성곱 신경망의 은닉층을 합성곱 신경망에서는 합성곱 층 이라고 한다.
2)합성곱 신경망의 편향

합성곱 신경망에 편향을 추가하고 싶다면
커널을 적용 후 더하면 된다.
6. 특성 맵의 크기 계산 방법
입력 크기, 커널크기, 스트라이드 값만 알면 특성맵 크기를 알 수 있다

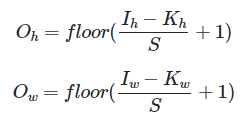
floor함수는 소수점을 버리는 역할이다
5x5 크기 이미지에 3x3커널을 사용하고 스트라이드1로 합성곱 연산을 하면
특성 맵 크기는 (5-3+1)x(5-3+1)=3x3이다. 즉 총 9번의 스텝이 필요하다.
패딩의 폭을 P라고 하고 패딩까지 고려한 식은 다음과 같다

7. 다수의 채널을 가질 경우의 합성곱 연산(3차원 텐서의 합성곱 연산)
지금까지는 채널(깊이)를 고려하지 않고 2차원 텐서로 가정하여 설명했다
하지만 실제로 합성곱 연산 입력은 '다수의 채널을 가진' 이미지 or 이전 연산의 결과로 나온 특성 맵일 수 있다.
이렇게 다수의 채널을 가진 입력 데이터를 가지고 합성곱 연산을 하려면 입력 데이터 채널 수와 커널 채널수가 같아야 한다
합성곱 연산을 채널마다 수행한 후 그 결과를 모두 더하여 최종 특성 맵을 얻는다.

위 그림은 3개의 채널을 가진 입력 데이터와 3개의 채널을 가진 커널의 합성곱 연산을 보여준다.
커널의 각 채널끼리 크기는 같아야한다.
각 채널간 합성곱 연산을 마치고 결과를 모두 더해 하나의 채널을 가지는 특성맵이 만들어진다.
주의) 위의 커널은 3개의 커널이 아니라 3개의 채널을 가진 1개의 커널이다
8. 3차원 텐서의 합성곱 연산
일반화를 해보자

3차원 텐서의 합성곱 연산

입력데이터와 커널을 합성곱 연산을 하여 Oh x Ow 채널 1의 특성맵을 얻었다.

하나의 입력에 여러개의 커널을 사용하는 합성곱 연산도 가능하다
다수의 커널을 사용한다면 '사용한 커널 수'는 합성곱 연산 결과로 나오는 '특성 맵의 채널수' 이다.
'커널의 크기', '입력 데이터의 채널 수' Ci, '특성 맵 채널 수' Co가 주어지면, 가중치 매개변수 개수를 구할 수 있다.
가중치는 커널의 원소들이므로 하나의 커널의 하나의 채널은 Ki × Ko개의 매개변수를 가지고 있다.
그런데 합성곱 연산을 하려면 커널은 '입력 데이터의 채널 수'와 동일한 채널 수를 가져야 한다.
그래서 하나의 커널이 가지는 매개변수의 수는 Ki × Ko × Ci이다.
이런 커널이 총 Co개가 있으므로 가중치 매개변수의 총 수 : Ki × Ko × Ci × Co 이다.
9.Pooling
합성곱 층 다음에는 풀링층을 추가하는것이 일반적이다.
풀링층에서는 특성맵을 다운샘플링하여 특성맵 크기를 줄이는 풀링 연산이 이루어진다.
최대 풀링, 평균 풀링이 사용되는데
우선 최대 풀링으로 풀링 연산을 이해해보자

풀링 연산에서도 합성곱 연산과 마찬가지로 커널과 스트라이드의 개념이 있다.
위의 그림은 스트라이드가 2일 때, 2 x 2 크기 커널로 맥스 풀링 연산을 했을 때 특성맵이 절반의 크기로 다운샘플링되는 것을 보여준다. 맥스 풀링은 커널과 겹치는 영역 안에서 최대값을 추출하는 방식으로 다운샘플링한다.
평균 풀링은 평균값을 추출하는 연산이 됩니다.
08-02 CNN으로 MNIST분류
#08-02
import torch
import torch.nn as nn
inputs=torch.Tensor(1,1,28,28)#배치 크기x채널x높이x너비
#첫번째 합성곱 층 구현
conv1=nn.Conv2d(1,32,3,padding=1)
#두번째 합성곱 층 구현
conv2=nn.Conv2d(32,64,kernel_size=3,padding=1)
#maxpooling구현
pool=nn.MaxPool2d(2)
#연결하여 모델 완성
out=conv1(inputs)
out=pool(out)
out=conv2(out)
out=pool(out)
#view로 tensor 펼치기
out=out.view(out.size(0),-1)
fc=nn.Linear(3136,10)
out=fc(out)
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torch.nn.init
device='cuda' if torch.cuda.is_available() else 'cpu'
#fix random seed
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
#parameter
learning_rate = 0.001
training_epochs = 15
batch_size = 100
#dataset 정의
mnist_train = dsets.MNIST(root='MNIST_data/', # 다운로드 경로 지정
train=True, # True를 지정하면 훈련 데이터로 다운로드
transform=transforms.ToTensor(), # 텐서로 변환
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/', # 다운로드 경로 지정
train=False, # False를 지정하면 테스트 데이터로 다운로드
transform=transforms.ToTensor(), # 텐서로 변환
download=True)
data_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)
#class로 모델 설계
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 첫번째층
# ImgIn shape=(?, 28, 28, 1)
# Conv -> (?, 28, 28, 32)
# Pool -> (?, 14, 14, 32)
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# 두번째층
# ImgIn shape=(?, 14, 14, 32)
# Conv ->(?, 14, 14, 64)
# Pool ->(?, 7, 7, 64)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# 전결합층 7x7x64 inputs -> 10 outputs
self.fc = torch.nn.Linear(7 * 7 * 64, 10, bias=True)
# 전결합층 한정으로 가중치 초기화
torch.nn.init.xavier_uniform_(self.fc.weight)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1) # 전결합층을 위해서 Flatten
out = self.fc(out)
return out
model=CNN().to(device)
criterion = torch.nn.CrossEntropyLoss().to(device) # 비용 함수에 소프트맥스 함수 포함되어져 있음.
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
total_batch=len(data_loader)#배치의 개수는 600, 배치 크기는 100개라 훈련데이터는 총 60000
#train model################################
for epoch in range(training_epochs):
avg_cost = 0 # 에포크당 평균 비용을 저장하기 위한 변수 초기화
for X, Y in data_loader: # 미니 배치 단위로 데이터를 꺼내옴. X는 입력 데이터, Y는 레이블
# 이미지 데이터는 이미 (28x28) 크기를 가지므로, 별도의 reshape 필요 없음
# 레이블 Y는 원-핫 인코딩이 아닌 정수형 클래스 레이블임
X = X.to(device) # 입력 데이터를 연산이 수행될 장치로 이동 (예: GPU)
Y = Y.to(device) # 레이블을 연산이 수행될 장치로 이동 (예: GPU)
optimizer.zero_grad() # 옵티마이저의 기울기 초기화
hypothesis = model(X) # 모델을 통해 예측값(hypothesis)을 계산 (순전파 연산)
cost = criterion(hypothesis, Y) # 예측값과 실제값 Y 간의 손실(cost) 계산
cost.backward() # 역전파 연산을 통해 기울기 계산
optimizer.step() # 옵티마이저를 통해 파라미터 업데이트
avg_cost += cost / total_batch # 현재 배치의 비용을 전체 배치 수로 나누어 누적
# 에포크가 끝날 때마다 평균 비용 출력
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost))
#test######################################
# 학습을 진행하지 않을 것이므로 torch.no_grad() 사용
with torch.no_grad():
# 테스트 데이터를 모델에 입력하기 위한 준비
X_test = mnist_test.test_data.view(len(mnist_test), 1, 28, 28).float().to(device) # 테스트 데이터셋의 크기를 맞추고, 연산을 위한 장치로 이동
Y_test = mnist_test.test_labels.to(device) # 테스트 데이터셋의 레이블을 연산을 위한 장치로 이동
# 모델 예측 수행
prediction = model(X_test) # 테스트 데이터에 대해 모델이 예측한 결과값
# 예측 결과와 실제 레이블 비교
correct_prediction = torch.argmax(prediction, 1) == Y_test # 예측된 클래스와 실제 레이블이 일치하는지 확인
# 정확도 계산
accuracy = correct_prediction.float().mean() # 정확도를 계산하기 위해 일치하는 예측의 평균을 구함
print('Accuracy:', accuracy.item()) # 정확도를 출력
08-03 깊은 CNN으로 MNIST 분류
#08-03 깊은 CNN으로 MNIST분류
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torch.nn.init
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 랜덤 시드 고정
torch.manual_seed(777)
# GPU 사용 가능일 경우 랜덤 시드 고정
if device == 'cuda':
torch.cuda.manual_seed_all(777)
#parameter
learning_rate = 0.001
training_epochs = 15
batch_size = 100
#define dataset
mnist_train = dsets.MNIST(root='MNIST_data/', # 다운로드 경로 지정
train=True, # True를 지정하면 훈련 데이터로 다운로드
transform=transforms.ToTensor(), # 텐서로 변환
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/', # 다운로드 경로 지정
train=False, # False를 지정하면 테스트 데이터로 다운로드
transform=transforms.ToTensor(), # 텐서로 변환
download=True)
#dataloader
data_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)
#build model############################
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.keep_prob = 0.5 # 드롭아웃 확률
# L1: 첫 번째 합성곱층 (Conv Layer)
# 입력 이미지 형태: (?, 28, 28, 1)
# Conv2d: 출력 채널 32개, 커널 크기 3x3, 스트라이드 1, 패딩 1
# ReLU: 활성화 함수
# MaxPool2d: 커널 크기 2x2, 스트라이드 2로 다운샘플링 -> 출력 형태: (?, 14, 14, 32)
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# L2: 두 번째 합성곱층 (Conv Layer)
# 입력 이미지 형태: (?, 14, 14, 32)
# Conv2d: 출력 채널 64개, 커널 크기 3x3, 스트라이드 1, 패딩 1
# ReLU: 활성화 함수
# MaxPool2d: 커널 크기 2x2, 스트라이드 2로 다운샘플링 -> 출력 형태: (?, 7, 7, 64)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# L3: 세 번째 합성곱층 (Conv Layer)
# 입력 이미지 형태: (?, 7, 7, 64)
# Conv2d: 출력 채널 128개, 커널 크기 3x3, 스트라이드 1, 패딩 1
# ReLU: 활성화 함수
# MaxPool2d: 커널 크기 2x2, 스트라이드 2, 패딩 1로 다운샘플링 -> 출력 형태: (?, 4, 4, 128)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2, padding=1))
# L4: 첫 번째 선형층 (Fully Connected Layer)
# 입력 노드 수: 4x4x128, 출력 노드 수: 625
# ReLU: 활성화 함수
# Dropout: 드롭아웃으로 과적합 방지, p=0.5
self.fc1 = torch.nn.Linear(4 * 4 * 128, 625, bias=True)
torch.nn.init.xavier_uniform_(self.fc1.weight) # 가중치 초기화
self.layer4 = torch.nn.Sequential(
self.fc1,
torch.nn.ReLU(),
torch.nn.Dropout(p=1 - self.keep_prob))
# L5: 최종 선형층 (Fully Connected Layer)
# 입력 노드 수: 625, 출력 노드 수: 10 (클래스 개수)
self.fc2 = torch.nn.Linear(625, 10, bias=True)
torch.nn.init.xavier_uniform_(self.fc2.weight) # 가중치 초기화
def forward(self, x):
out = self.layer1(x) # 첫 번째 합성곱층 통과
out = self.layer2(out) # 두 번째 합성곱층 통과
out = self.layer3(out) # 세 번째 합성곱층 통과
out = out.view(out.size(0), -1) # 선형층에 입력하기 위해 텐서를 Flatten
out = self.layer4(out) # 첫 번째 선형층 통과
out = self.fc2(out) # 최종 선형층 통과
return out # 최종 출력 반환
# CNN 모델 정의
model = CNN().to(device)
criterion = torch.nn.CrossEntropyLoss().to(device) # 비용 함수에 소프트맥스 함수 포함되어져 있음.
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
total_batch = len(data_loader)#배치의 수는 600개
#train#########################33
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader: # 미니 배치 단위로 꺼내온다. X는 미니 배치, Y느 ㄴ레이블.
# image is already size of (28x28), no reshape
# label is not one-hot encoded
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost))
#test#########################
# 학습을 진행하지 않을 것이므로 torch.no_grad()
with torch.no_grad():
X_test = mnist_test.test_data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())'개발 > AI' 카테고리의 다른 글
| [MCP] Model Context Protocol란 (0) | 2025.04.25 |
|---|---|
| [논문 리뷰] A joint Sequence Fusion Model for Video Question Answering and Retrieval (1) | 2024.09.25 |
| [Pytorch] 07. 순환 신경망(RNN) (0) | 2024.08.05 |
| [OpenCV] 컴퓨터 비전과 딥러닝 / Ch05 / 연습 문제 (2) | 2024.08.03 |
| [OpenCV] 컴퓨터 비전과 딥러닝 / Ch04 / 연습 문제 (0) | 2024.08.03 |

